- Implemented visualization for light-dark domain in RL-Viz:

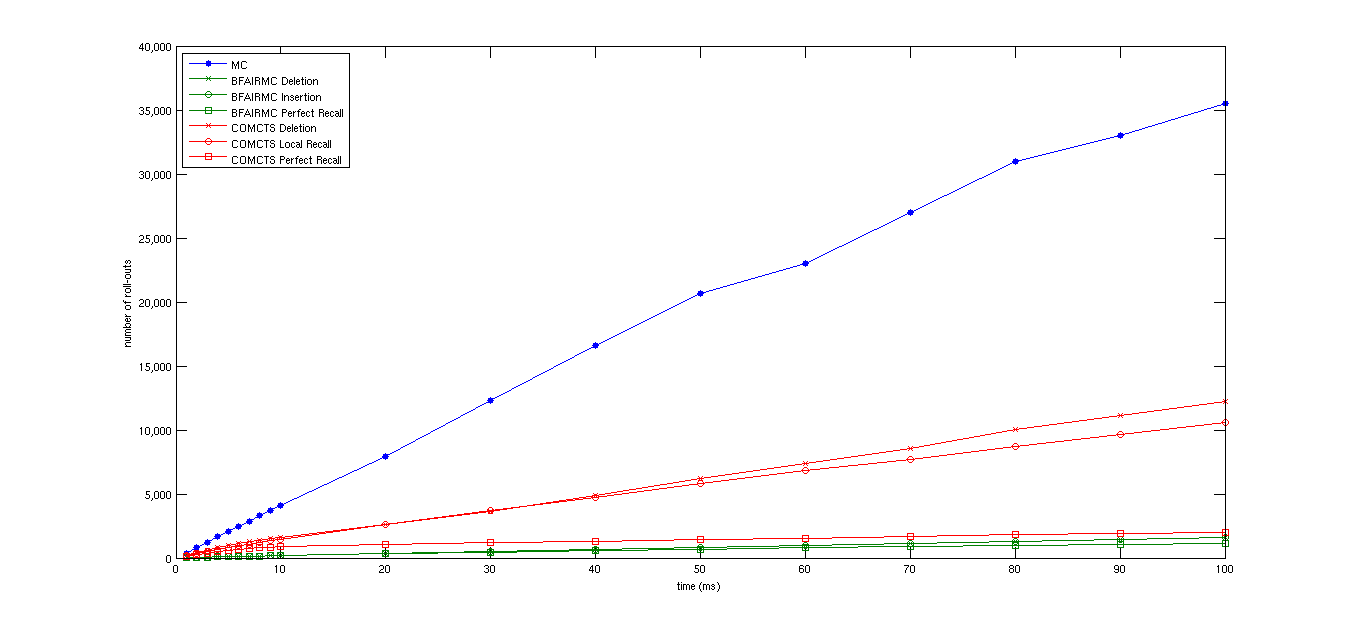
- Finished time-based performance experiment for light-dark domain (see below)
- Thesis:
- Included the experiment mentioned before
- Some small language / content corrections
- Environment: 10x10 discrete state space light-dark domain
- Max. steps: 20
- Discount factor: 0.95
- Number of episodes: 2,000
 |
| time vs roll-outs |
 |
| time vs mean |